Today we introduced the ability to copy the text in document scans and deliver that text to you programmatically via our API + Webhooks.
Document Scans
Before this update, our PDFs were really just jpegs under the hood — they didn’t contain any actual text or metadata.
Now, our PDFs contain real text. Specifically, we’re extracting the text we detect in the image using OCR, and then overlaying the detected text directly on the image — sort of like a stamp. Surprisingly, this stamping method is very common with PDFs.
This update affects the PDF files we generate, which means you can copy the text wherever the PDF is rendered — in the Stable Dashboard, our notifications, or anywhere else you may have downloaded the file.
API + Webhooks
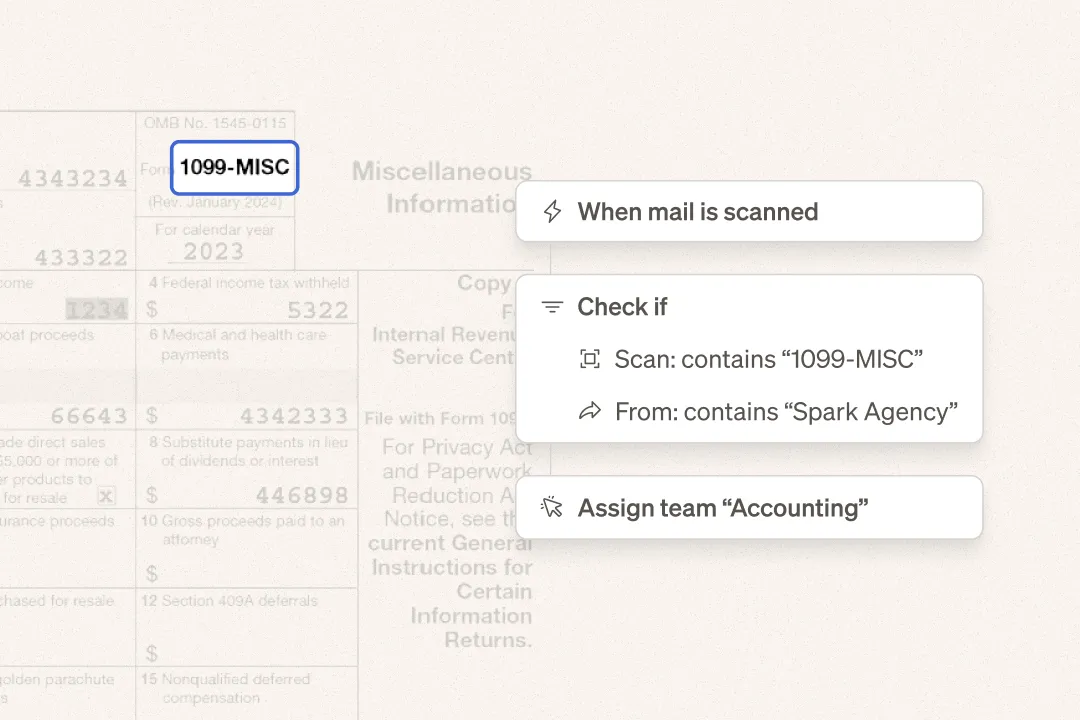
The OCR results from each document scan will be included in our API + Webhook payloads. These results will contain the text and the location of the text within the document.
We hope this information will enable new use cases for document handling like invoice resolution, custom data extraction, document classification, and more.
Let us know what you think of this feature once you try it out!